算法和应用
DFS
深度优先搜索(Depth-First Search,简称 DFS)是一种用于图的遍历和搜索的算法,它从图中的一个起始顶点开始,尽可能深地访问顶点,直到无法继续前进,然后回溯到之前的顶点,继续深入其他分支。DFS 通常用递归或栈来实现,确保在深度方向上优先遍历。
以下是 DFS 算法的一般步骤:
- 从起始顶点开始,将其标记为已访问。
- 遍历与当前顶点相邻的未访问顶点,选择其中一个未访问顶点作为下一个深度遍历的目标,然后递归地进行 DFS。
- 如果无法继续深度遍历(即当前顶点没有未访问的邻居),则回溯到上一个顶点,继续遍历其他未访问的邻居。
- 重复步骤 2 和步骤 3,直到所有顶点都被访问。
图中 DFS 实现的框架与 树的遍历 类似,不同点在于需要使用 visit 数组记录已经访问过的节点,避免重复遍历:
function DFS(G, v, visited):
visited[v] ← true
for each neighbor u of v in G.adjacent[v]:
if not visited[u]:
DFS(G, u, visited)
图在 邻接矩阵 和 邻接表 中的 DFS 都遵循这个框架,两者的不同点在于获取 v 的邻居 u 的方式不同。
邻接矩阵
在 邻接矩阵 中,我们定义一个递归函数 dfs,函数从 start 顶点出发,输出当前结点,然后递归地去访问所有与其相邻的顶点。
注意递归前需要保证下一个顶点未被访问过,这样可以避免重复访问结点以及死循环。
// 全局变量,标记顶点是否被访问过
int visited[MAX_VERTICES];
// 递归函数,从 start 顶点出发
void dfs(int start) {
visited[start] = 1;
printf("%d ", start);
// 依次访问 start 的邻接顶点
for (int i = 0; i < MAX_VERTICES; i++) {
// 递归的两个条件:
// 1. 顶点 (start, i) 之间存在边
// 2. 顶点 i 未被访问过
if (adjMatrix[start][i] == 1 && !visited[i]) {
// 递归调用
dfs(i);
}
}
}
邻接表
邻接表 的递归思路与 邻接矩阵 一致,唯一的区别就是访问邻接顶点方式的不同。
在 邻接矩阵 中,通过遍历矩阵中的一行来访问相邻顶点。在 邻接表 中,通过遍历链表来访问相邻顶点。
// 全局变量,标记顶点是否被访问过
int visited[MAX_VERTICES];
// 递归函数,从 start 顶点出发
void dfs(struct Graph* graph, int start) {
visited[start] = 1;
printf("%d ", start);
// 依次访问 start 的邻接顶点
struct Node* temp = graph->adjacencyList[start];
while (temp) {
int adjVertex = temp->data;
// 递归条件:顶点 i 未被访问过
if (!visited[adjVertex]) {
dfs(graph, adjVertex);
}
temp = temp->next;
}
}
BFS
广度优先搜索(Breadth-First Search,简称 BFS)是一种用于图的遍历和搜索的算法,它从图中的一个起始顶点开始,逐层地访问与该顶点相邻的顶点,然后再访问这些相邻顶点的邻居,以此类推。BFS 通常用 队列 来实现,确保按照广度优先的顺序访问顶点。
以下是 BFS 算法的一般步骤:
- 将起始顶点放入队列中,标记为已访问。
- 从队列中弹出一个顶点并访问它。
- 遍历该顶点的所有未被访问的邻居,将它们放入队列中,并标记为已访问。
- 重复步骤 2 和步骤 3,直到队列为空。
BFS 的伪代码实现如下所示,基于 邻接矩阵 或 邻接表 的 BFS 都遵循这个框架:
function BFS(G, start):
visited[start] ← true
enqueue(Q, start)
while Q is not empty:
v ← dequeue(Q)
process(v)
for each neighbor u of v in G.adjacent[v]:
if not visited[u]:
visited[u] ← true
enqueue(Q, u)
邻接矩阵
实现 BFS 时,首先添加起始顶点进入队列中,然后不断从队列中取出顶点,并添加该顶点的未访问相邻顶点进入队列。重复直到队列为空。
在 DFS 中,visited 数组是各个递归函数都需要访问的数据结构,为了方便起见,可以定义为全局变量。
在 BFS 中,由于算法实现是基于迭代而非递归,所以 visited 和队列可以定义为局部变量。
// 从 start 开始遍历图
void bfs(int start, int vertices) {
// 队列 q
queue q;
// 标记顶点是否被访问过
int visited[MAX_VERTICES];
// 添加初始顶点
q.enqueue(start);
visited[start] = 1;
// 一直遍历到队列为空
while (q.size() > 0) {
// 从队列头部取出结点作为当前结点
int currentVertex = q.dequeue();
// 输出当前结点
printf("%d ", currentVertex);
// 将当前结点的所有 相邻的未访问顶点 添加到队列中
for (int i = 0; i < vertices; i++) {
if (adjMatrix[currentVertex][i] == 1 && !visited[i]) {
q.enqueue(i);
visited[i] = 1;
}
}
}
}
邻接表
实现思路与 邻接矩阵 方式一致,不同点在于访问相邻顶点的方式不同。
void bfs(struct Graph* graph, int start) {
// 队列 q
queue q;
// 标记顶点是否被访问过
int visited[MAX_VERTICES];
// 添加初始顶点
q.enqueue(start);
visited[start] = 1;
// 一直遍历到队列为空
while (front != rear) {
// 从队列头部取出结点作为当前结点
int currentVertex = q.dequeue();
// 输出当前结点
printf("%d ", currentVertex);
// 将当前结点的所有 相邻的未访问顶点 添加到队列中
struct Node* temp = graph->adjacencyList[currentVertex];
while (temp) {
int adjVertex = temp->data;
if (!visited[adjVertex]) {
q.enqueue(adjVertex);
visited[adjVertex] = 1;
}
temp = temp->next;
}
}
}
最小生成树
最小生成树(Minimum Spanning Tree,MST)是在一个连接所有顶点的无向图中,通过选择一部分边而形成的树,使得树的总权重(或成本)最小。
准确的 MST 定义如下:在无向图 中, 代表连接顶点 和顶点 的边,而 代表此边的权重,若存在 为 的子集且 为树,使得 最小,则此 为 的 最小生成树。
MST 满足以下特点:
- 包含图中的所有顶点。
- 通过选择一些边而形成一个树结构,没有环路。
- 边的总权重最小。
prim 算法
Prim 算法通过 逐步扩展顶点集合 来构建最小生成树:从一个初始顶点出发,每次都选择一条 连接生成树与外部顶点的最小权重边,并将该顶点并入生成树,直到所有顶点都被包含。
prim 算法步骤 如下:
- 选定一个起始顶点作为生成树的根。
- 初始化生成树,只含有该顶点。
- 在所有 连接生成树与未加入顶点的边 中,选取权重最小的一条,并将对应顶点加入生成树。
- 重复步骤 3,直到所有顶点均被纳入生成树。
- 得到的生成树即为原图的 最小生成树。
prim 是一种 贪心算法,这里关键在于理解什么叫做 所有连接生成树与未加入顶点的边:
当我们已经有一个部分生成树(初始时只有一个顶点),它把图中的顶点分成两类:
- 已加入生成树的顶点集合
- 尚未加入生成树的顶点集合
此时,
- 所有连接生成树与未加入顶点的边,就是一端在 \(T\) 内、另一端在 \(V-T\) 内的边。
- 这些边正好构成了一个“割(cut)”,也叫“横切边”。
Prim 算法的贪心思想就在这里:每次都从这组横切边里挑出一条 权重最小的边,把它对应的未加入顶点纳入生成树。
这样保证了:
- 每次扩展都是局部最优(加入的边在候选集合里是最小的)。
- 最终能够得到全局最优的最小生成树(证明基于“割性质”,不是重点这里不说明)。
参考 prim 算法的流程图如下:
举个实际例子,对于以下的无向图,假设我们从顶点 a 出发使用 prim 算法寻找最小生成树,会逐步选择出 ab、bc、ci、cf、fg、gh、cd 以得到最小生成树:
kruskal 算法
Kruskal 算法是一种用于求解 最小生成树(MST)的贪心算法。Kruskal 算法的基本思想是从边的权重最小的边开始,逐步构建生成树,确保不会形成环路。
以下是 Kruskal 算法的一般流程:
- 初始化一个空的生成树,开始时生成树中没有边。
- 将图中的所有边按照权重 从小到大进行排序。
- 依次 从排序后的边列表中选取边,加入生成树,但要确保 添加该边不会形成环路。
- 重复步骤 3,直到生成树包含了所有的顶点,即生成树中的边数等于顶点数减 1。
- 返回生成树作为 最小生成树。
参考 kruskal 算法的流程图如下:
继续使用上文中 prim 中的无向图作为例子,使用 kruskal 算法,会依次选择 hg、ic、gf、ab、cf、cd、ah 以得到最小生成树:
最短路径
dijkstra 算法
Dijkstra 算法是一种用于计算 单源最短路径 的经典算法,适用于 带非负权重 的有向或无向图。
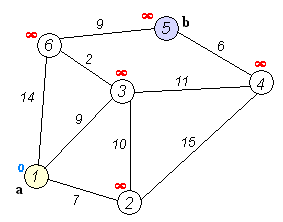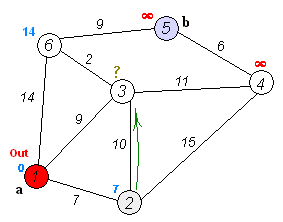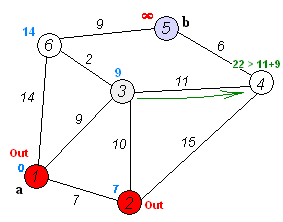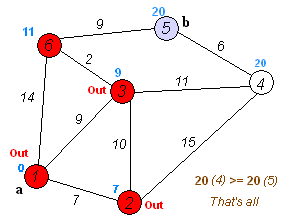
Dijkstra 算法是一种 贪心算法。它的 核心思想 是:从起点出发,不断“扩展”到距离起点最近的节点,并利用这些节点去尝试更新其他节点的最短路径,直到所有节点的最短路径都被确定。
换句话说,算法始终保持一个 “已确定最短路径的集合”,并且在每一步中把离起点最近的“候选节点”加入其中:
prim 算法和 dijkstra 算法的核心步骤十分类似:
- 两个算法都用一个集合(已确定的顶点集合)逐步扩展。
- 每次都要在“已选顶点集合”与“未选顶点集合”之间,挑选一个“最优”的候选顶点加入集合。
但是 prim 比较的是比较的是 边的权重(只看与生成树相连的边),dijkstra 比较的是 从源点出发的路径长度(边的累计权重)。
🛠️ dijkstra 算法需要定义以下 数据结构 :
dist[]:数组,dist[v]表示起点到节点v的 当前已知最短路径长度。- 初始化时:
dist[source] = 0,其余节点均为∞。
- 初始化时:
visited[]:布尔数组,表示某个节点的最短路径是否已经被最终确定。- 初始时:所有节点均为
false。
- 初始时:所有节点均为
✨ dijkstra 算法流程 如下:
- 初始化
- 设起点为
source。 dist[source] ← 0- 对于其他顶点
v,dist[v] ← ∞ visited[v] ← false
- 设起点为
- 主循环(重复 |V| 次,即所有顶点都被处理完)
- 从所有 未访问 的顶点中,找到一个
dist[]值最小的顶点u。 (这意味着:当前已知路径中,u是离起点最近的尚未确定的节点。) - 将该顶点标记为已访问:
visited[u] ← true。 - 对于
u的每个邻居v:- 如果
v未被访问,并且通过u到达v的路径更短(即dist[u] + w(u,v) < dist[v]), 则更新:
(这一步就是“松弛操作”,表示尝试通过dist[v] ← dist[u] + w(u,v)u改进到v的最短路径。)
- 如果
- 从所有 未访问 的顶点中,找到一个
- 结束
- 当所有顶点都被访问后,
dist[v]就保存了起点到各个顶点的最短路径长度。
- 当所有顶点都被访问后,
Dijkstra 算法流程可以通过以下流程图理解:
Dijkstra 的考察侧重于手工模拟其过程,代码实现一般不会考察,这里给出算法的简单 伪代码实现,帮助各位理清其中的处理细节。
function Dijkstra_Simple(Graph, source):
对于图中每个顶点 v:
dist[v] ← ∞ // 起点到 v 的距离初始化为无穷大
visited[v] ← false // 所有顶点初始都未被访问
dist[source] ← 0 // 起点到自身距离为 0
重复 |图中顶点数| 次:
u ← 所有未访问的顶点中 dist[u] 最小的顶点
visited[u] ← true // 标记 u 已被访问
对于 u 的每个相邻顶点 v:
边权重 weight ← 图中边(u, v) 的权重
如果 v 未访问 且 dist[v] > dist[u] + weight:
dist[v] ← dist[u] + weight // 通过 u 到 v 更短,更新最短路径
return dist[] // 表示起点到所有顶点的最短路径
假设顶点的个数为 ,边的个数为 ,那么 最佳实现(使用了优先队列)的 dijkstra 算法时间复杂度为 。
floyd 算法
Floyd Warshall 是一种基于 动态规划 的方法,用于求解任意两个顶点之间的最短路径,它适用于带权有向图。
该算法的核心思想是尝试使用每一个顶点作为中转点,逐步更新所有顶点对之间的最短路径。对任意两点 ,判断是否可以通过一个中间点 得到更短路径:
这个过程会遍历所有可能的中转点 ,不断优化路径。

✨ 算法具体流程如下:
初始化距离矩阵
dist:dist[i][j] = 0(若i=j)dist[i][j] = 边权(若i→j有边)dist[i][j] = ∞(其余情况)
三重循环更新最短路径
for k in 所有顶点: for i in 所有顶点: for j in 所有顶点: if dist[i][k] + dist[k][j] < dist[i][j]: dist[i][j] ← dist[i][k] + dist[k][j]输出 dist 矩阵 :表示所有顶点对之间的最短路径长度。
若顶点数为 ,则 Floyd Warshall 算法的时间复杂度为 ,该算法适合在算法题中兜底使用,因为实现比较简单,建议大家熟练掌握代码实现。
拓扑排序
拓扑排序 这样一种对图中顶点的排序方式:
将图中的所有顶点排序,使得对于每一条有向边
u→v,顶点u都排在v之前。
拓扑排序 主要应用于 DAG(有向无环图)或 AOV 网,这种图没有环路,因此可以对其进行拓扑排序。
首先需要区分 AOV 和 AOE 这两个概念,注意 拓扑排序 适用于 AOV,关键路径 适用于 AOE。
AOV 网
AOV(Activity on Vertex Network)网是一种以顶点表示活动或任务的网络模型。每个 顶点 代表一个 任务或活动,而 边 表示任务之间的 依赖关系。在AOV网中,任务或活动通常表示为顶点,而依赖关系(任务的先后顺序)表示为有向边。
算法步骤
计算 拓扑排序 的算法有两种,一种是 Kahn 算法(基于入度),另一种是 DFS+栈 的实现。
Kahn算法Kahn 算法的核心思想是 依次选取入度为 0 的顶点进行输出,其具体步骤如下:
- 选择一个没有前驱顶点(入度为 0)的顶点作为起始顶点,将其加入拓扑排序的结果序列中。
- 从图中移除该顶点以及与之相关的边(即将与之相邻的顶点的入度减 1)。
- 重复步骤 1 和步骤 2,直到所有的顶点都被加入到拓扑排序的结果序列中,或者发现图中存在环路。
- 如果所有的顶点都被成功加入结果序列,那么这个序列就是拓扑排序的结果。
下图展示了一个采用 Kahn 算法输出 AOE 网中的 拓扑序列 的实例:
此外,可以通过 DFS+栈 得到 拓扑序列,其步骤如下:
- 对图进行深度优先遍历。
- 每个节点 DFS 结束后将其压入栈中。
- 最后将栈中元素逆序输出,就是 拓扑排序 结果。
DFS 过程中,每个节点在其所有后继节点访问完成后才被加入栈中,因此栈中元素的逆序正好满足 拓扑排序 所需的“前驱先于后继”的约束。
拓扑排序 的时间复杂度通常为 ,其中 是顶点的数量, 是边的数量。这个算法非常适合于解决任务调度和依赖关系问题,因为它可以确定任务的执行顺序或依赖关系的合理性。
关于拓扑排序,还需要关注以下几点:
- 拓扑排序的结果 可能不唯一,因为在构建过程中往往会出现多个入度为 0 的顶点,不同的选择顺序会产生不同的合法排序结果。
- 如果图中 存在环路,那么 无法进行拓扑排序,因为无法找到入度为 0 的顶点作为起始顶点。
关键路径
关键路径 是指 AOE 网(Activity On Edge Network)中,从源点到汇点所经过的 最长路径。这条路径决定了整个项目完成所需的最短时间,因此被称为 关键 路径。
AOE 网
AOE(Activity on Edge Network)网是一种以边表示活动或任务的网络模型。每条边代表一个任务或活动,而顶点通常表示事件,表示任务的开始或完成时间。
为了理解 关键路径,首先需要明确 AOE 网中的以下概念:
- 源点:在 AOE 网中仅有一个入度为 的顶点,称为开始顶点,表示整个工程的开始。
- 汇点:在 AOE 网中仅有一个出度为 的顶点,称为结束结点,表示整个工程的结束。
- 关键路径的长度:完成整个工程的最短时间,也是 AOE 网中从源点到汇点的 最长路径。
- 关键活动:关键路径 上的活动。
- 活动的时间余量:某个活动可以被延迟的最大时间,而不会影响整个项目的最短完成时间(总工期)。
ve(k):事件 的最早可以发生时间。vl(k):事件 的最晚可以发生时间。
有几个概念比较重要,还需要进行进一步的阐述:
事件和活动在 AOE 网中,边代表活动(Activity),顶点代表事件(Event)。
- 活动(边):表示一个具体的工作、任务或操作,具有确定的持续时间。一个活动必须在其起点事件“发生”之后才能开始。
- 事件(顶点):表示一个时间点,通常是某些活动的“开始”或“结束”条件已经满足,代表某种逻辑上的时刻状态。
通俗来讲:活动是“做某事”,事件是“可以开始做某事的时间点”
事件的发生时间在 AOE 网中,一个事件的“发生”是指其所有前驱活动都已完成,这标志着“条件成熟”,从该事件出发的活动才可能被启动。
两个关键时间:
| 时间名称 | 含义 | 数学符号 |
|---|---|---|
| 最早发生时间 | 某事件最早可以发生的时间 | ve(i) |
| 最晚发生时间 | 某事件最晚必须发生的时间(不影响工期) | vl(i) |
事件发生的判断逻辑:
一个事件是否可以发生,不看它的出边活动,而是看它的所有前驱活动(入边)是否完成:
- 若某事件
i的所有进入活动(任务)都已完成 → 则事件i发生; - 一旦事件
i发生,其所有出边活动 可以开始,但 不必须同时开始; - 出边活动的实际开始时间取决于它们自身的调度灵活性(浮动时间)。
“活动的时间余量” 在 AOE 网中指的是:
一个活动可以被延迟的最大时间,而不会影响整个项目的最短完成时间(总工期)。
首先,为什么要有时间余量呢?因为在 AOE 网络中,不是所有活动都在 关键路径 上。
- 关键路径上的活动:必须准时进行,没有时间余量(余量 = 0)
- 非关键路径上的活动:允许适当延迟,但必须不阻碍项目的最晚结束时间
时间余量可以通过以下数学公式计算:
对于一个活动 ,持续时间为 ,其时间余量:
其中:
- :起点事件 i 的最早发生时间
- :终点事件 j 的最晚发生时间
- :活动持续时间
关键路径 上的所有活动都是 关键活动,它是决定整个工程的关键因素,因此可通过加快关键活动来缩短整个工程的工期。
关键路径和关键活动具有以下典型特征:
关键活动的时间余量为 0:即对某活动 有
说明该活动不能被延迟任何时间,否则将影响总工期。
关键活动连接的事件满足:
即活动的起点和终点事件的最早发生时间等于最晚发生时间。它们必须在确定的时间点发生,不能提前也不能推迟。
关键路径是工程中的最长路径:它决定了整个项目从开始到结束所需的最短时间,也即项目总工期。
关键路径可能有多条:若多个路径的总时长都等于项目的最短完成时间,这些路径上的活动都必须受到严格监控。
算法步骤
求解 关键路径 的 核心思路 在于找到所有 最早发生时间 和 最晚发生时间 相同的结点,连接这些结点即可得到关键路径。
所以在求关键路径的算法中,我们需要依次计算每个顶点的最早发生时间(ve)和最晚发生时间(vl),然后判断哪些顶点的 ve 和 vl 相等。
为了得到关键路径,需要分三步计算:
1. 计算最早发生时间 ve
- 从 源点 出发,设
ve(start) = 0; - 按照 拓扑排序 的顺序依次计算其他顶点的最早发生时间:
其中 表示 \(v_k\) 的所有前驱结点。 含义:顶点 \(v_k\) 的最早开始时间,取决于它所有前驱活动完成的最晚时间。
2. 计算最迟发生时间 vl
- 从 汇点 出发,设
vl(end) = ve(end); - 按照 逆拓扑排序 的顺序依次计算其余顶点的最迟发生时间:
其中 表示 \(v_k\) 的所有后继结点。 含义:顶点 \(v_k\) 的最迟开始时间,取决于它所有后继活动最早开始的最早约束。
3. 确定关键路径
- 若某个顶点满足
ve(i) = vl(i),则说明该顶点没有时间浮动,必须严格按时发生; - 将这些顶点按拓扑顺序连接起来,得到关键路径。
用图表达树
当表达式中存在共享的子表达式时,二叉树可能不是存储这些表达式的最有效方式,因为它会重复存储共享的子表达式。在这种情况下,可以使用 有向无环图(DAG)来表示表达式,这样可以避免重复,并且更有效地表示表达式。
比如对于表达式 (x + y) * ((x + y) / x),用二叉树和 DAG 的表示如下图: